Core disparity algorithm working and CUDA performance

First three months of 2019 were spent improving the core stereo photogrammetry disparity algorithm. This consisted of a major overhaul changing from a per block algorithm to per pixel algo. This is working in Matlab and an example of a disparity map is above. The image is false coloured so each colour change reflects a 1 pixel disparity change between the stereo pair.
The image shows a distance to a near shed roof of approx 35-40m and the large building in the background is approx 150m away and I have tested out to 800m. Pixel accuracy is approximately 1/4 pel.
The last two months have been moving to a new image platform - a pair of Hikvision 20MP colour camera using the SONY IMX183. I’ve also been porting the Matlab code to CUDA and early results give a full 20MP depth image within a few seconds.
If we look below we can see the 3D view of the scene from Google ( Their photogrammetry is pretty amazing)

Then below is an early version of the CUDA 20MP image - still a bit noisy, but note the church spire in red which is 800m away and at 2-3 pixels of disparity.
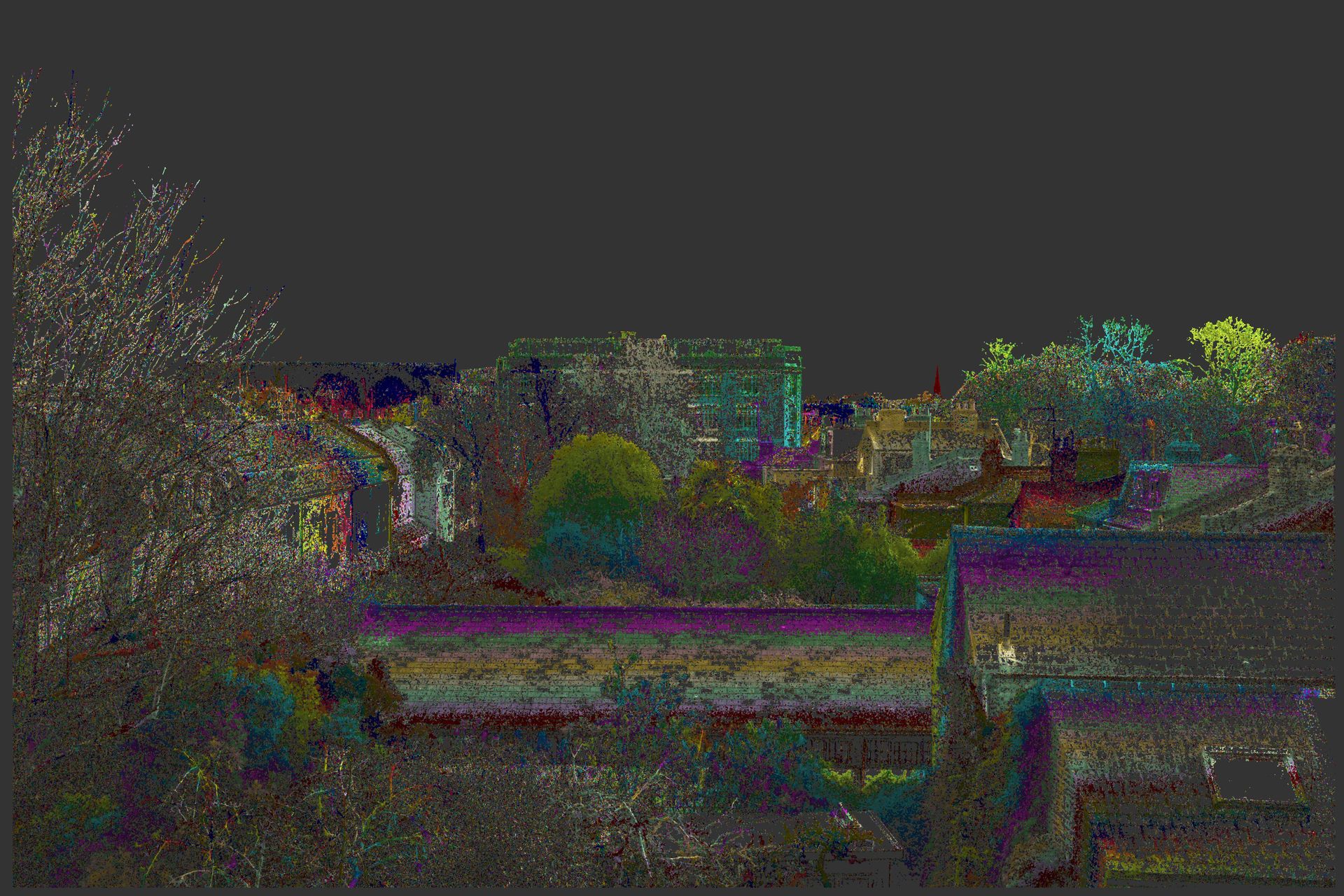
Click here to see the full 20MP image and note detail like television aerials etc.
Click here to see the left and right stereo pair. NB these are demosaiced but the core algorithm operates on the raw sensor CFA data, also it does not rectify the images.
Next steps are to move the algorithm to consider previous frames, with a target framerate between 2-6fps.
Please email me jimd -at- yantantethera.com if you have any questions.





 Research is focussed on object detection with Deep Learning, tracking in video, re-identification and real-time performance. We have worked in Internet video and camera technology for many years, but have been focussed on this area since early 2014, attending CVPR2014/2015, BMVA2015 and similar.
Research is focussed on object detection with Deep Learning, tracking in video, re-identification and real-time performance. We have worked in Internet video and camera technology for many years, but have been focussed on this area since early 2014, attending CVPR2014/2015, BMVA2015 and similar.
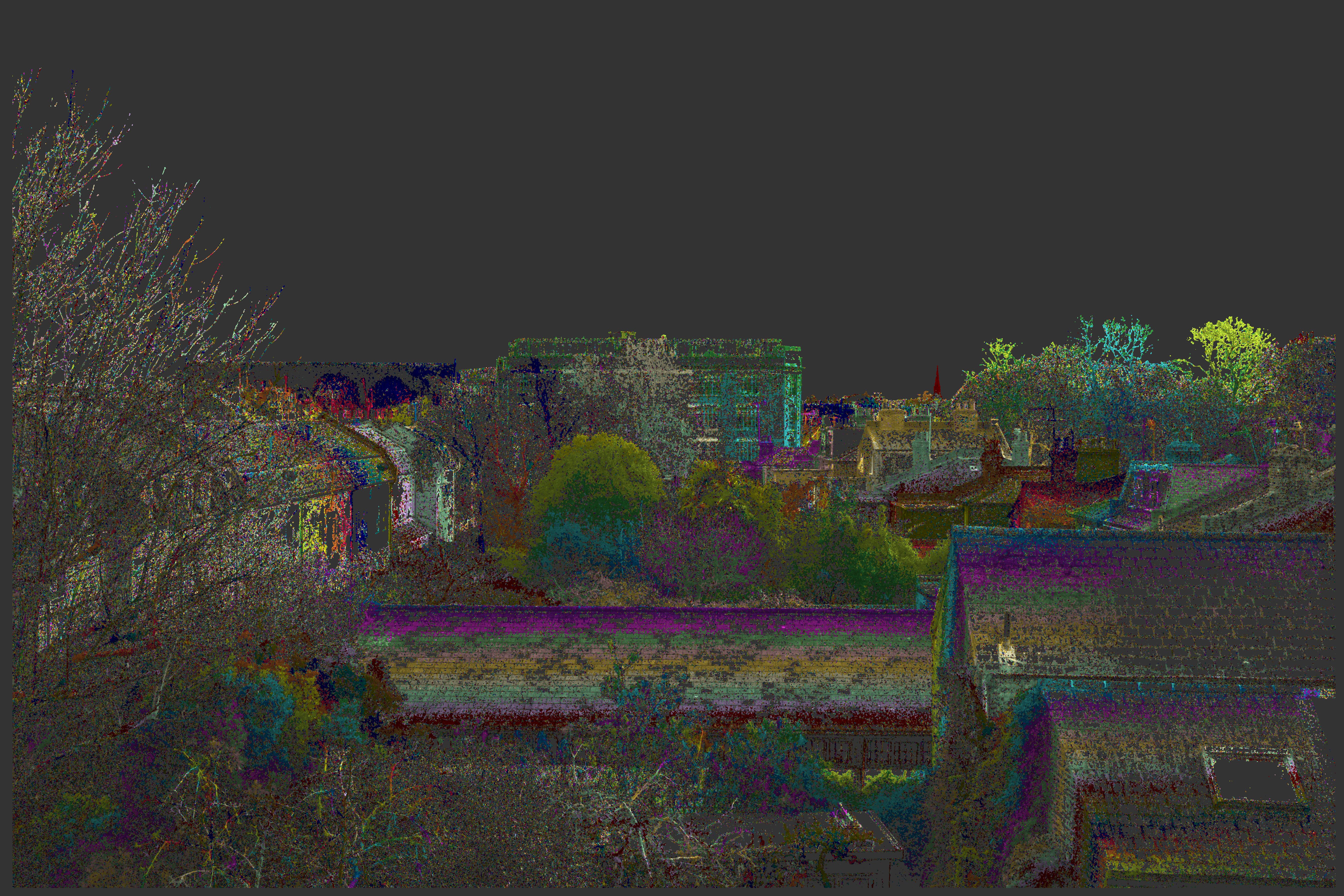{kind=link}
{kind=link}
{kind=link}